
Since November 2011, the Center for Open Science has been involved in an ambitious project: to repeat 100 psychology experiments and see whether the results are the same the second time round. The first wave of results will be released in tomorrow’s edition of Science, reporting that fewer than half of the original experiments were successfully replicated.
The studies in question were from social and cognitive psychology, meaning that they don’t have immediate significance for therapeutic or medical treatments. However, the project and its results have huge implications in general for science, scientists, and the public. The key takeaway is that a single study on its own is never going to be the last word, said study coordinator and psychology professor Brian Nosek.
“The reality of science is we're going to get lots of different competing pieces of information as we study difficult problems,” he said in a public statement. “We're studying them because we don't understand them, and so we need to put in a lot of energy in order to figure out what's going on. It's murky for a long time before answers emerge.”
Tuning up science's engines
A lack of replication is a problem for many scientific disciplines, from psychology to biomedical science and beyond. This is because a single experiment is a very limited thing, with poor abilities to give definitive answers on its own.
Experiments need to operate under extremely tight constraints to avoid unexpected influences from toying with the results, which means they look at a question through a very narrow window. Meanwhile, experimenters have to make myriad individual decisions from start to finish: how to find the sample to be studied, what to include and exclude, what methods to use, how to analyse the results, how best to explain the results.
This is why it’s essential for a question to be peered at from every possible angle to get a clear understanding of how it really looks in its entirety, and for each experiment to be replicated: repeated again, and again, and again, to ensure that each result wasn’t a fluke, a mistake, a result of biased reporting or specific decisions—or, in worst-case scenarios, fraud.
And yet, the incentives for replications in scientific institutions are weak. “Novel, positive and tidy results are more likely to survive peer review,” said Nosek. Novel studies have a “wow” factor; replications are less exciting, and so they're less likely to get published.
It’s better for researchers’ careers to conduct and publish original research, rather than repeating studies someone else has already done. When grant money is scarce, it’s also difficult to direct it towards replications. With scientific journals more likely to accept novel research than publications, the incentives for researchers to participate in replication efforts diminish.
At the same time, studies that found what they set out to find—called a positive effect—are also more likely to be published, while less exciting results are more likely to languish in a file drawer. Over time, these problems combine to make “the published literature … more beautiful than the reality,” Nosek explained.
The more blemished reality is that it's impossible for all hunches to be correct. Many experiments will likely turn up nothing interesting, or show the opposite effect from what was expected, but these results are important in themselves. It helps researchers to know if someone else has already tried what they’re about to do, and found that it doesn’t work. And of course, if there are five published experiments showing that something works, and eight unpublished experiments showing it doesn’t, the published literature gives a very skewed image overall.
Many researchers are working to combat these problems in different ways, by tackling both the journals and the rewards systems in institutions. Some have called for all PhD candidates to be required to conduct at least one replication in order to graduate, although this could run the risk of making replication boring, low-prestige grunt work and do little to enhance its popularity.
Scratching the surface
In 2011, the Reproducibility Project: Psychology, coordinated by the Center for Open Science, started a massive replication effort: 100 psychology experiments from three important psychology journals, replicated by 270 researchers around the world.
As with all experiments, there were complicated decisions to be made along the way. Which experiments were most important to replicate first? How should they decide what level of expertise was necessary for the researchers doing the replicating? And most importantly, what counts as a successful replication?
The last question wasn’t an easy one to answer, so the researchers came up with a multitude of ways to assess it, and applied all the criteria to each replication.
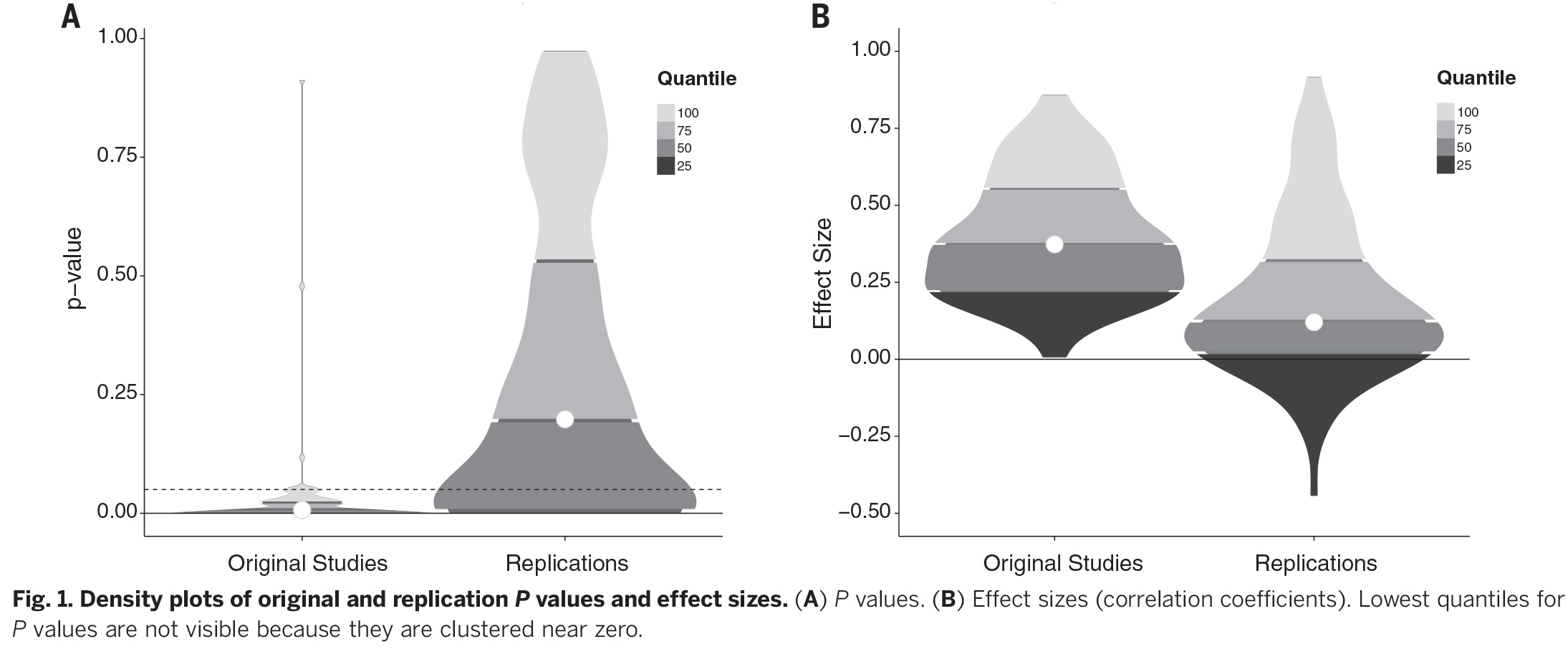
Of the 100 original studies, 97 had results that were statistically significant; only a third of the replications, however, had statistically significant results. Around half of the replications had effect sizes that were roughly comparable to the original studies. The teams conducting the replications reported whether they considered the effect to be replicated, and only 39 percent of them said it did. These criteria suggest that fewer than half of the originals were successfully replicated.
So what does this mean? It’s easy to over-simplify what a successful or failed replication implies, the authors of the Science paper write. If the replication worked, all that means is that the original experiment produced a reliable, repeatable result. It doesn’t mean that the explanation for the results is necessarily correct.
There are often multiple different explanations for a particular pattern, and one set of authors might prefer one explanation, while others prefer another. Those questions remain unresolved with a simple replication, and they need different experiments to answer those concerns.
A failed replication, meanwhile, doesn’t necessarily mean that the original result was a false positive, although this is definitely possible. For a start, the replication result could have been a false negative. There’s also the possibility that small changes in the methods used for an experiment could change the results in unforeseen ways.
What’s really needed is multiple replications, as well as tweaks to the experiment to figure out when the effect appears, and when it disappears—this can help to figure out exactly what might be going on. If many different replications, trying different things, find that the original effect can’t be repeated, then it means that we can probably think about scrapping that original finding.
No clear answers, just hints. Obviously.
Part of what the Center for Open Science hoped to demonstrate with this effort is that, despite the incentives for novel research, it is possible to conduct huge replication efforts. In this project, there were incentives for researchers to invest, even if they weren’t the usual ones. “I felt I was taking part in an important groundbreaking effort and this motivated me to invest heavily in the replication study that I conducted,” said E. J. Masicampo, who led one of the replication teams.
Like all experiments, the meta-analysis of replications wasn’t able to answer every possible question at once. For instance, the project provided a list of potential experiments for volunteers to choose from, and it’s likely that there were biases in which experiments were chosen to be replicated. Because funding was thin on the ground, less resource-intensive experiments were likely to be chosen. It’s possible this affected the results in some way.
Another replication effort for another 100 experiments might turn up different results: the sample of original experiments will be different, the project coordinators might make different choices, and the analyses they choose might also change. That’s the point: uncertainty is “the reality of doing science, even if it is not appreciated in daily practice,” write the authors.
“After this intensive effort to reproduce a sample of published psychological findings, how many of the effects have we established are true?” they continue. Their answer: zero. We also haven’t established that any of the effects are false. The first round of experiments offered the first bit of evidence; the replications added to that, and further replications will be needed to continue to build on that. And slowly, the joined dots begin to form a picture.
Science, 2015. DOI: doi/10.1126/science.aac4716 (About DOIs).
This post originated on Ars Technica UK
Open all references in tabs: [1 - 9]